上周六(8 月 31 日),在上海黄浦江边状如螺旋的 “西岸漩心”,大模型独角兽 MiniMax 举办了第一届 “伙伴日”。
这是这家成立近3年、估值已达30亿美元的公司第一次办线下发布会:他们回顾了创业起点;披露了目前的关键用户数据——日均30亿次AI交互量,处理3万亿Token;和技术架构更新。
现场最受瞩目的是MiniMax当天首发的视频生成大模型abab-video-1。目前可支持以文字生成6秒的2K视频,25帧率,用户已能在海螺AI网页版体验该模型。OpenAI年初发布的Sora则能生成60秒、30帧率的2K视频,尚未对普通用户开放。
由MiniMax视频生成大模型制作的短片《魔法硬币》,MiniMax称其中每个场景都由大模型生成,未经任何修改。
发布会所在的“西岸漩心”被巨大的螺旋式阶梯环绕,游人可沿着步道一直走到顶层露台,眺望浦东风景。这是一条上升、平缓,然后再上升、平缓,最终达到顶点的路。此时AI领域似乎也处在螺旋中的相对平缓期。
当MiniMax创始人闫俊杰放映完由视频生成模型制作的动画短片后,观众席传来数声尖叫。至少3位在场的投资人说,视频生成模型是他们当天最在意的成果。
但视频生成模型本身不新鲜了,自OpenAI年初发布Sora,数家中国公司跟进这一方向。
“期货”也在成为行业关键词:GPT-5、GPT-4o的语音视频功能、Sora……它们要么上线晚于预期,要么亮相多时后仍未大规模公测。据我们了解,国内“六小龙”(MiniMax、月之暗面、智谱AI、百川智能、零一万物、阶跃星辰6家大模型独角兽)今年的基础模型或多模态模型的更新时点也多晚于原计划。
发布结束后,闫俊杰被问起如何看待技术进展放缓。他说,一条上升、平缓、再上升的螺旋曲线合理且健康,从今年全球 AI 算力和算法性能的指数级增长中,闫俊杰看到 Scaling Laws 仍在奏效:
“虽然GPT-4o和GPT-4性能差不多,但速度快了10倍,这也意味着算法的进步。计算量多了不止10倍,算法也快了10倍时,没道理训练不出一个更好的模型。”
MiniMax仍在一个个推进计划中的节点。数月前我们对话闫俊杰时,他提到今年视频生成模型会变得实用,这是他们的目标之一。
他当时也提到,处理更长文本的关键技术方法是 Linear Attention,那时他们还没实现这一点,而现在它成为 MiniMax 新架构的基石之一,另一个则是他们此前已研发的 MoE(混合专家系统模型)。MiniMax 的新基础模型 abab 7 就是一个使用 MoE+Linear Attention 的多模态模型。
我们整理了这次发布会闫俊杰的主题演讲,并摘录了会后群访的部分内容,其中包含MiniMax对评估技术进展和应对激烈竞争的想法与做法。
闫俊杰演讲整理
Intelligence with Everyone 和由此而来的 3 个判断
大家好,我是MiniMax的创始人IO(闫俊杰的昵称),欢迎来到我们的第一次伙伴日活动。
首先给大家介绍一下MiniMax创立前的故事。在创业前,我做了超过十年的人工智能研发。当时的人工智能是什么呢?最有代表性的应用就是人脸识别和AlphaGo。过去,大部分场景都是需要定制模型,但是又没法做到每个场景都定制,因此人工智能对很多人而言只是高大上的概念。这让作为从业者的我越来越困惑:我们花这么大力气研究人工智能,到底为了什么?
2021年春节,我回了趟老家看望外公。他们那代人经历的一生,是我小时候最喜欢听的故事。80岁的外公想写一本回忆录,但他不会打字,也没有足够的精力去查询资料。理论上AI很合适来完成这件事情,但是很遗憾,那时的AI做不到。
这件事让我意识到,AI 发展的终极目标,是变得更加通用,能帮助到每个人。三个词总结,就是 Intelligence with Everyone。
当我想通了这一点,一切都开始变得清晰。这让我找回了对AI研究的初心和热爱,以及一种强烈的使命感。
但问题接踵而来:该如何开始?
为了追求这个目标,在2021年底,我们成立了MiniMax。在一个不到100平米的房间里写下初心和路径,其中的三个判断,直至今日我们都依然坚定选择。

闫俊杰展示创业之初,MiniMax团队x写下的初心和路径判断。
第一,我们认为下一代人工智能是无限接近通过图灵测试的智能体,交互自然,触手可及,无处不在;
第二,要实现这样的目标,像造芯片一样是一个巨大的系统工程,不能只做5%、10%的提升,需要能带来数量级提升的技术突破。
第三,因为这件事很难,所以我们要坚定地分步走、拆解问题。我们判断应该先从容错率高的闲聊、写作切入。当技术一步一步提升,就可以做更强大的、以解决问题为导向的应用。最终给每个人带去智能的延展。
Intelligence with Everyone,和用户共创智能,不仅是目标,也是最高效,甚至是唯一的路径。很多时候不是我们的技术在帮助用户,而是用户在帮助我们。有了多元化用户的参与和反馈,才有更好的智能。
日均30亿次交互,处理3万亿Token
从2021年12月9日成立到今天,刚好996天。目前,每天MiniMax的大模型和终端用户(包括自有的产品+开放平台伙伴)会进行30亿次交互。
30亿次是什么概念?这包含每天处理超3万亿文本token,每天生成2000万张图和每天生成7万小时语音。
3万亿文本token又是什么概念呢?相当于一天内体验完3000段人生。
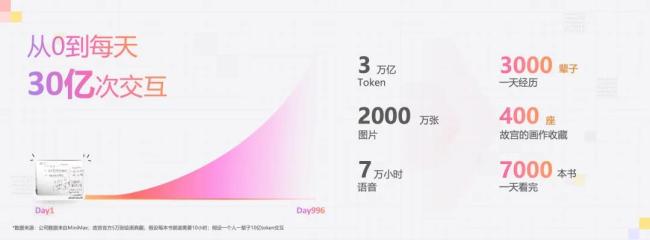
这30亿次连接背后,是来自全球各地、陪伴我们一起成长的用户。无论男女老幼,他们都有共同特点——多元、充满创意和活力。我们努力在用好的技术与他们共创惊喜时刻,这也是我们更加专注于改进技术的底层源动力。而这些用户真实的故事,汇聚成了MiniMax模型每日超3亿分钟的交互时长。
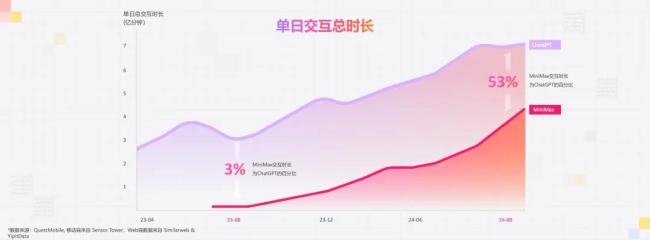
交互时长也是处理量的最佳近似指标,在很多第三方的数据网站上,像 QuestMobile、Sensor Tower 都可以查到相关数据。
一年前的今天,当时我们每天的交互时长大概只是ChatGPT的3%,今天这个时长超过50%。这也是目前所有中国公司里最大的交互时长。多个数据表明,我们可能是国内大模型日处理量最大的公司。
继续提升AI渗透率的方法:降低错误率、无限长度输入/输出、多模态
但即使取得了一定的进展,我们所连接的用户还没有达到全球人口的 1%,只有 0.8%,距离 Intelligence with Everyone 还有很长的路要走。
如何从今天的1%增长到100%?最重要的是提高AI产品在用户中的渗透率和使用深度。
基于过去两年多的多次复盘和总结,我们认为提升这两点只能通过一件事来完成:“科学技术是第一生产力”。
放在大模型领域看——每当我们的模型有重大提升,处理速度有显著提升时,就可以看到用户使用场景和用户使用深度显著变高。反过来,这里也有一个真实案例:我们曾有一个bug导致对话重复错误率变高,当天的对话量就掉了40%。这也解释了我们坚持技术创新的最底层原因。
今天的AI应用,要取得渗透率和使用深度上质的提高,还有很多技术难关要攻克。我们认为最重要的三个优化方向是:
01、如何让模型的错误率持续降低:
目前的模型还是有相对较高的错误率,有时惊艳,有时不靠谱。这也是制约模型处理复杂任务的原因,因为复杂的任务往往需要多个步骤,而较高的错误率会导致失败率指数增加。降低模型的错误率,是一个能够让模型处理复杂任务的最根本的前提,这个也是能够增加用户使用深度的核心手段。
02、无限长的输入和输出:
为什么这件事情重要?很简单的原因就是人具备这个能力。传统大模型计算需求随着输入输出处理量平方上升,很快就会达到算力无法负担的上限,需要底层创新解决。
03、多模态:
从生活中不难发现,文字交互只是很小的一部分,更多的是语音和视频交互。多模态内容,比如声音,图文和视频已经成为信息传递的主流。为提高渗透率,多模态是必经之路。
MoE+线性注意力机制:更快+更长
那么,如何攻克这些技术难关?在大模型领域,我们认为在同样的能力范围内,“快就是好”。
我们都知道大语言模型里面有 Scaling law,意思是说在算法一样的情况下,拥有更多的训练数据量和参数量就能达到更好的效果。因此,在两个性能类似的模型中,训练和推理更快的那个,可以更有效地利用算力资源迭代更多的数据,从而能够有一个更好的模型能力。所以我们认为,快就是好,这是一个朴素但很容易被人忽视的哲学。
“快”是MiniMax底层大模型的核心技术研发目标。围绕这点,我们做了很多技术革新,这边分享两个具体的例子。
第一,MoE。在 MoE 架构还没有被行业认可时,我们就做出了一个决定,在国内率先完成核心 MoE 算法技术路线的突破。我们对比了 Dense 模型(稠密模型)和非原生的 MoE、原生的 MoE。在上一代 MiniMax 的模型 abab 6.5s 里,我们用 MoE 的模型比 Dense 模型快 3-5 倍。这个也是为什么 6.5s 模型能每天处理几十亿次交互的核心原因。我们的 6.5s 足够快,所以得到了广泛部署。

在解决MoE问题时,我们遇到过很多技术挑战,但花了很多精力最终解决问题之后,让我们坚定了自研的信心和直面复杂技术挑战的勇气。
这种勇气使得我们在过去几个月又解决了一个更难的技术挑战,也就是我要说的第二点——Linear Attention。
Linear Attention 不仅能带来一个级别的提升,也是解决无限长度输入和无限长度输出的关键一步。简单来说,Linear Attention 就是通过把 Transformer 中的计算左乘找到一个右乘的近似,把传统模型架构中输入长度和计算复杂度之间平方增长的关系,变成了线性关系。(注:随处理文本量的增加,一次函数的线性关系带来的计算量增长会越来越小于二次函数的平方关系。)
尽管在 2019 年就有人曾提出这种想法,但从来没有人在大规模的模型上做到 work。我们团队找到了一种新的归一化方式来代替 Softmax(一种标准 Transformer 里的 attention 采用的计算操作),以及一种位置编码来提供计算的非线性。除此之外,我们找到了一种高效的方式,使大规模训练 Linear Attention 成为可能。
今年 4 月,我们开始作为第一批钻研 Linear Attention 的 AI 公司,成功研发出了新一代的基于 MoE+ Linear Attention 的模型,真正可以比肩 GPT-4o 的水平。
以国际上领先的三个模型为例,GPT-4o、Claude3.5 sonnet、abab 7,可以看到在输入的长度变长的时候,速度的提升相比非 Linear Attention 的模型有非常显著的变化。在处理 10 万 token 时,新模型的处理效率可达 2-3 倍,并且长度越长,模型效率提升越明显。理论上,模型可以处理的 token 接近无限长。
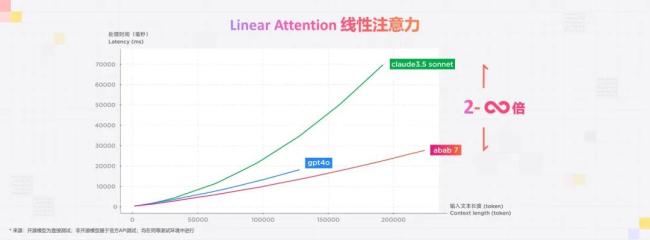
在做 Linear Attention 的过程中,我们惊喜地发现其实 GPT-4o 也是这么做的。这件事给了我们很大的信心,在探索前沿技术的道路上,我们跟国际上最好的公司殊途同归。MiniMax 团队具备了越来越强的技术创新能力,我们需要继续坚持,不断找到加速技术进步的创新,才真的有机会成为全球顶级的技术公司。
我们意识到,即使我们做了 MoE,做了 Linear Attention,有了好几倍的提升以后,还仍有很多其他的技术创新需要我们去做。有多个能带来几倍提升的技术后,再去做乘法,才有可能让 AGI 成为现实。abab 7 模型的核心技术正是基于 MoE+Linear Attention。
多模态进展和视频生成模型
除此之外,我们在 abab 7 上还构建了多模态理解能力。此外,我们把类似的创新技术应用在文本等多个模型上,包括声音和视频。
今天,MiniMax的语音模型增加了在国际上领先、且非常实用的功能:
01、多个语种:支持包括日语、韩语、西班牙语、法语、粤语等10多个语种。MiniMax也成为全球第一个拥有地道粤语语音模型能力的公司;
02、情绪表达:生成的语句超拟人,拥有细腻的情绪变化;
03、音乐:MiniMax的第一款音乐模型面世了。这个模型有极高的艺术性和可塑性,相信会给我们的创造者和伙伴们带去非常多的新玩法和惊喜。
我们的语音模型是从星野、海螺和Talkie等产品中打磨出来的,我们坚持在自己的产品和API中使用相同的模型。
MiniMax推出了我们的第一个视频模型,也有可能是国内目前最好的视频生成模型。相比市面上的视频模型,我们的模型独特性有:
01、文本响应好:得益于MiniMax在文本上不断积累,指令遵循好;
02、压缩率高 :得益于我们在网络架构上的经验积累,对高动态、变化多的信息有较好的表现力,其中 Linear Attention 所带来的高推理效率功不可没。
03、风格多样:我们在全球拥有多元化的用户分布。无论是3D电影大片场景,还是2D动画均可驾驭;无论是中式风格还是科幻、美漫,都难不倒它。
当我们把更新后更强大的MiniMax模型能力综合起来,会发生什么呢?我们尝试用多种模型生成一段短片《魔法硬币》,并且没有任何人工修改。后续,我们会将视频背后应用的prompt公布,为大家提供一个“如何只用模型来生成高质量的视频内容”的参考。未来,我们会把所有新推出的模型和能力,都同步在MiniMax开放平台和星野、海螺AI中体验。由AI生成片段制作的短片《魔法硬币》放映结束。
我这边有一枚魔法硬币。我们很希望,我们的AI能够像这枚魔法硬币一样,帮助很多人创造无穷的想象力,把AI带给每个人。
视频、声音和音乐模型已完全发布、可使用;新模型 abab 7 将在未来几周发布
在模型与产品的更新方面,声音模型、音乐模型、视频模型目前已经完全公布。
此外,新一版能从速度和效果上对标 GPT-4o 的模型 abab 7 会在未来几周内发布。
MiniMax的现有模型和产品。
所有的模型,包括最好的音乐模型、声音模型,最好的视频模型,以及我们认为有可能会变成最好的文本模型,都可以在MiniMax开放平台里体验。
我们的开放平台目前为止已经有超过3万名开发者,超过2000家付费客户,并且仍在持续快速增长。同时,这些模型也可以第一时间在海螺AI中体验,海螺AI也是我们在个人助手领域一个主力的产品。当把复杂的模型一起来用时,到底能组合出来什么样复杂的、更高级的玩法,我们会放在内容社区产品星野APP里面。
作为理想主义且脚踏实地的MiniMax人,我们仍然在努力前行;两年半后的今天,很幸运我们的同行者中多了那么多在座的各位,以及我们全球各地日益增长的用户们。
感谢各位的持续关注与支持。希望与各位携手努力,和 MiniMax 一起,把人类的智能边界再向外推动一点,真正实现 Intelligence with Everyone。
群访的部分摘录
谈技术:在我们自己的测试集上,所有国产模型都比GPT-4差
Q:今年的一个现象是,很多进展变成了期货,上线或公测延迟,你怎么看现在AI技术进步的速度?什么时候会是下一个重要的Milestone?
闫俊杰:核心标志可能不是GPT-4o或Claude3的发布,也不是我们做了一个MoE模型。真正本质的变化是,现在所有模型都有两位数的错误率,什么时间点能有一个模型把错误率降低到个位数?
为什么这非常本质?因为这个变化可以让很多复杂任务从不能做变成能做。复杂任务需要多步相乘,乘起来,错误率就会放大。这就是为什么现在Agent跑不通,GPT-store也跑不通,本质还是模型不够好。
那什么时间能实现?我们可以看到,现在不少公司有了不止10倍多的算力。算法也在进步:GPT-4o和GPT-4虽然性能差不多,但速度可能快了10倍,这也意味着算法的进步。计算量多了不止10倍,算法也快了10倍时,没道理训练不出一个更好的模型。
所以我的判断是,如果 Scalling law 是对的,这个模型一定会出现,标志就是产生个位数错误率的模型。
Q:怎么判断每家大模型公司的模型水平?现在大家都说自己很牛。
闫俊杰:这个事很难,我们也经历过当评价标准不够好时,模型迭代误入歧途。
我只能说我们目前的方式:我们的开放平台有3万多个开发者,付费客户有几千家,其中有些要求我们一定保证效果,我们就基于这些场景构建了测试集,这是来自多家客户的真实使用。
你看其他排行榜,基本GPT-4都排到中间了,但在我们这个测试集上,确实GPT-4、GPT-4o最靠前,包括我们的模型在内,其它模型都跟GPT-4有本质差距,而且越难的问题差距越大。从这个评估看,我们的提升空间还挺大。
Q:今年视频生成赛道非常激烈,MiniMax做视频生成模型,在你们整个布局里的必要性是什么?
闫俊杰:我们一直的目标就是要做多模态输出。少有基础大模型公司声音做得很好,但我们声音和音乐都做得非常好,今天我们把视频也做得非常好。
本质是一个基本道理:大模型对人类社会的核心意义就是做更好的信息处理,而我们每天看的大部分信息都不是文字,而是多模态内容:打开小红书都是图文,打开抖音都是视频,甚至打开拼多多买东西也都是图片。
所以为了提高用户覆盖度和用户深度,唯一办法就是能输出多模态内容。
Q:MiniMax曾把80%的算力和资源放到MoE上,未来对大模型的研发还会保持这样的投入水平吗?怎么分配产品和大模型间的投入资源?
闫俊杰:我现在对技术的理解逐渐变得简单:要大投入去做的技术研发,不应该追求10%的提升,而应追求几倍的提升。因为前者你不做也会有人做;后者很多时候我们自己不做,外面没人做,而它对满足用户需求又很重要。
所以我们在什么样的技术方向上最愿意花钱?核心判断是我们认为这个方向能不能带来几倍的提升。
谈产品:星野不是陪伴型聊天产品,是一个内容社区
Q:如何看待Character.AI被收购和陪伴类AI的发展前景?
闫俊杰:解释一件事,我们的产品,如星野,底层设计不是陪伴用户聊天,而是一个内容社区。用户可以在其中创建角色、故事,甚至世界观,另一些用户可以与其他人创造的世界观互动,类似小说的交互体验。
在ChatGPT等聊天产品里,体验主要来自模型;而星野的很多输入来自用户,所以每个用户得到的个性化输出是来自模型加另一些用户的创作。这是核心的区别。
至于 Character.AI 被收购,所有人都得到了好处,是一个 happy ending。
Q:一些用户反馈,使用星野或Talkie时,会发现虚拟角色很难和他们进行深度聊天,导致用户流失,你们怎么应对?
闫俊杰:本质上还是模型不够好,没有很长的记忆,理解不了特别复杂的指令。这也是我们为什么我们要让模型能够处理无限长的输入和输出,让它理解力变强,以及有更多模态。
这里面也包括更多创作者激励。社区这件事是所有的互联网产品里面最难做的,要一步一步演化。我们看十年前,B站上可能还是金坷拉,但现在B站显然有了很多知识、AI内容,有各种各样的东西,这就是一个演化过程。
谈竞争:大厂的竞争让我们更快看到赢的本质
Q:最近朱啸虎说,大模型六小龙最佳的归宿是被大厂并购,因为商业化太难。你们看到的主要难点是什么?用户付费习惯,还是模型调用成本,还是中国企业数字化程度不高?
闫俊杰:当一个产品没人用或者不赚钱时,肯定不能怪用户、怪生态,只能怪自己。
腾讯在2000年时也不知道该怎么赚钱,尝试无数商业化变现方案都失败了,最终找到了移动增值业务,后来慢慢找到了QQ,找到了游戏,都会经历这么一个过程。这个事(商业化)是对一个行业的考验,如果能通过就能出来,通不过确实应该关掉。
Q:如、、快手的飞船,现在出现了很多星野的同类产品,MiniMax怎么提升壁垒?
闫俊杰:这整体还是一件好事。电动车、手机、移动互联网,都是有好多公司进行了长期激烈的竞争,最终使中国产品全球领先。
我们作为一家小创业公司,如果在竞争中打不赢,那我们就应该被淘汰,就应该关掉,其实也没有其他选择。
大厂的竞争还带来一个好处,就是让我们能更快看清,创业公司能赢的底层是什么。比如买量,大厂的实力可能是你千百倍,你在这里和它竞争可能没用。
我们能做的就是无限放大能让我们变强的事,有两点:一是如何提升技术,二是如何跟用户做更好的共创。
Q:产品竞争外,怎么看今年的大模型价格战?
闫俊杰:大模型价格战客观上非常大地提高了模型调用量。很多传统企业也开始愿意用大模型,他们觉得反正成本低,出错了多调用一次就好。
也正是因为竞争激烈,push国内各家必须把模型做好,到了一定阶段后,发现在海外也有竞争力,比如在东南亚或一些地区,之前觉得可能必须用GPT,但GPT的语言支持其实不够好,国内模型,至少在非英语上,目前已经可以和GPT不相上下。
竞争既然不能避免,我们看到乐观的一面:国内大模型的使用量在显著增长,中国模型在海外越来越有竞争力。这是两个积极的变化。
涉事博主:未受任何人指使,也未从该视频中获得非法利益,未指使网友进行评论。