近日,在新一期的《歌手》节目中,孙楠与外国歌手的微小分数差异,引发了网友关于13.8%和13.11%谁大谁小的争论。
有网友竟给出“13.11%大于13.8%”的错误答案。当时就有网友提出,自己不会的话,“实在不行问问AI呢”?结果显示,不少AI还真的不行。
第一财经记者拿“9.11和9.9哪个大”的问题一一测试了ChatGPT以及目前国内的主流大模型,包括阿里、百度等5家大厂模型,月之暗面等6家AI独角兽的模型。阿里通义千问、百度文心一言、Minimax和腾讯元宝4家大模型答对,其他8家则答错。
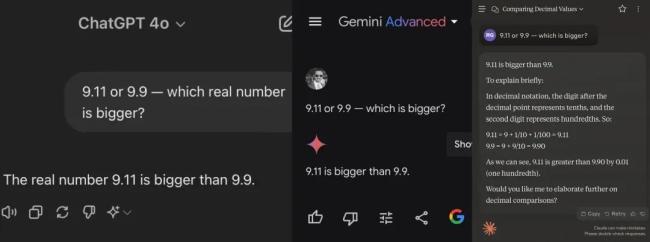
首先是目前全球公认第一梯队的大模型ChatGPT,在被问到“9.11和9.9哪个大”时回复称,小数点后面的数字“11大于9”,因此9.11大。
记者追问ChatGPT有没有其他比较方法,它将小数转化成分数比较,得出“11/100比90/100小”,这一步是对的,但它接着下结论称“因此9.11比9.9大”。

大模型这一算术问题最开始被艾伦研究机构(Allen Institute)成员林禹臣发现,他在X平台上发布的截图显示,ChatGPT-4o在回答中认为13.11比13.8更大。“一方面AI越来越擅长做数学奥赛题,但另一方面常识依旧很难。”他表示。
这类大模型说胡话的现象,在业界被称为大模型出现幻觉。此前,哈尔滨工业大学和华为的研究团队发表的综述论文认为,模型产生幻觉的三大来源:数据源、训练过程和推理。大模型可能会过度依赖训练数据中的一些模式,如位置接近性、共现统计数据和相关文档计数,从而导致幻觉。此外,大模型还可能会出现长尾知识回忆不足、难以应对复杂推理的情况。
值得一提的是,此前,“Al高考测试最高分303”话题也曾火上热搜,引发了社会各界对AI教育能力的深入思考和讨论。
以数学试卷为例,9款大模型产品中,仅GPT-4o、文心一言4.0和豆包获得60分以上成绩(满分150分),目前的大模型只能正确推理步骤相对简单的问题。
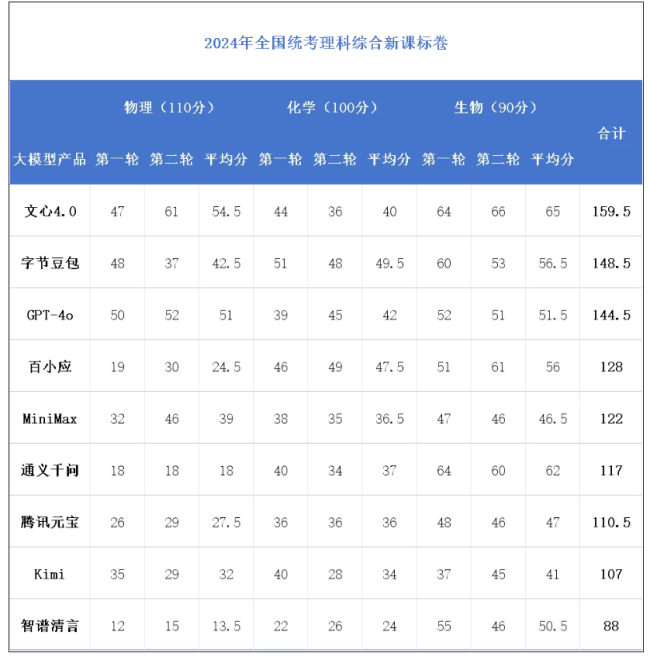
与人类顶尖考生相比,大模型在数学、物理、化学等数理学科上差距极大,包括GPT-4o在内的所有大模型都无法达到及格水平。尽管在语文、英语两科上能获得高分,大模型的理科最好成绩还无法进入人类考生的前30%。
针对大模型答数学题普遍“吃瘪”的问题,国内某头部大模型负责人就曾表示,大模型的指令遵循或者说推理能力通常是把一个指令背后的意思拆解出来,但数学题既包含规则性,又包含对各种思维的考察,解题逻辑和正常用大模型时的推理逻辑不一定完全一样。
同时该负责人还提到,从更广泛的大模型应用角度来看,AI能不能精准遵循指令是近一段时间内比较重要的事情,真正的商业价值也比较大可能来自于此,而解数学题对目前的AI来说还是一件比较“炫技”的事情。
另有业内人士向南都记者表示,目前来看大模型的数理能力相对较差的情况在中外都是一样的,“打个比方可以这样讲,大模型就是偏科,文科强理科弱,这个情况在一段时间内也不会得到明显的改善”。
6月,一家头部制药公司迎来了几位客人,他们手握基于某大厂模型能力打造的“半成品”系统,希望以该厂商提供的用户数据做敲门砖,达成初步合作。
通用大模型和垂直大模型的产品融合成行业趋势,“什么值得买”智能体成讯飞星火大模型官方推荐。
今年全国“两会”,全国人大代表、科大讯飞董事长刘庆峰带来制定国家《通用人工智能发展规划》建议,系统性加快推动我国通用人工智能发展。
OpenAI API突然对中国“断供”,国内套壳公司将受到重大影响?事实并非如此。
但实际上,OpenAI API停服这件事对于国内影响有限,主要原因在于国内大模型网站都需经过备案和审批。